
Миф о наказании за дублированный контент
- Что такое дублированный контент?
- Сколько в Интернете дублируется?
- Что думают Google по поводу дублированного контента?
- Причины дублирования контента
- TL; DR

Многие люди больше боятся дублирования контента, чем спам-ссылок.
Существует так много мифов о дублирующемся контенте, что люди на самом деле думают, что это повлечет за собой наказание, и что их страницы будут конкурировать друг с другом и причинять вред их сайту. Я вижу сообщения на форумах, темы Reddit, технический аудит, инструменты и даже новостные сайты SEO, публикующие статьи, которые показывают, что люди явно не понимают, как Google относится к дублирующемуся контенту.
Google пытался уничтожить мифы о дублированном контенте много лет назад. Сьюзан Моска разместила в блоге Google для веб-мастеров в 2008 году :
Давайте уложим это раз и навсегда, ребята: нет такого понятия, как «штраф за дублирование контента». По крайней мере, не так, как большинство людей подразумевают, когда говорят это.
Вы можете помочь своим коллегам-вебмастерам, не увековечивая миф о штрафах за дублирование контента!
Извини, мы подвели тебя, Сьюзен.
Что такое дублированный контент?
По данным Google :
Дублированный контент обычно относится к существенным блокам контента внутри или между доменами, которые либо полностью совпадают с другим контентом, либо заметно схожи. Главным образом, это не обманчиво по происхождению.
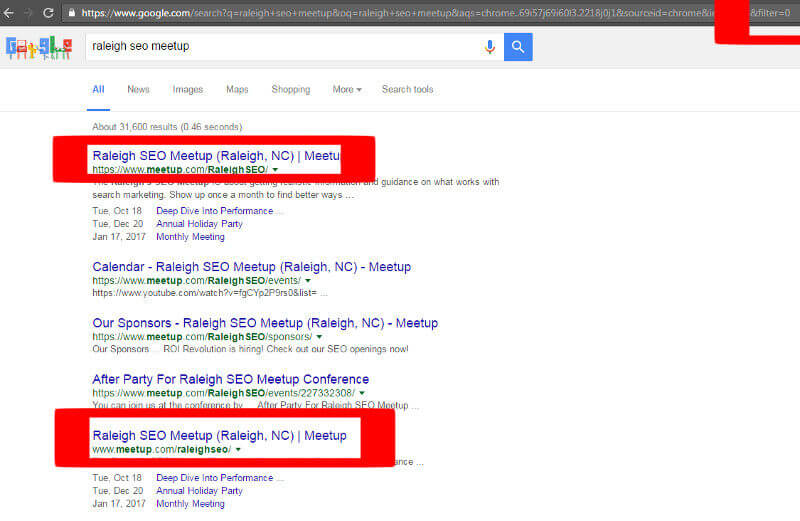
Люди ошибочно принимают дублированный контент за то, как Google его обрабатывает. Действительно, дубликаты просто фильтруются в результатах поиска. Вы можете убедиться в этом сами, добавив & filter = 0 в конец URL и удалив фильтрацию.
Добавление & filter = 0 в конец URL-адреса страницы в поиске «raleigh seo meetup» покажет мне одну и ту же страницу дважды. Я не говорю, что Meetup проделал хорошую работу с этим, поскольку они фактически указывают на то, что обе версии (в данном случае HTTP и HTTPS) являются правильными в использовании канонических тегов, но я думаю, что это показывает, что одна и та же страница (или аналогичные страницы) фактически индексируются, и показывается только наиболее релевантное. Дело не в том, что страница обязательно конкурирует или наносит какой-либо вред самому сайту.
Сколько в Интернете дублируется?
По словам Мэтта Каттса, От 25 до 30 процентов Интернета - дублированный контент , Недавнее исследование, проведенное Raven Tools на основе данных их инструмента аудита сайта, показало аналогичный результат: 29 процентов страниц имели дублирующийся контент ,
Что думают Google по поводу дублированного контента?
Многие замечательные посты были опубликованы Googlers. Я собираюсь дать вам краткое изложение лучших частей, но я также рекомендую прочитать посты.
- Дублированный контент не приводит к наказанию вашего сайта.
- Гуглеры знают, что пользователи хотят разнообразить результаты поиска, а не одну и ту же статью снова и снова, поэтому они решили объединить и показать только одну версию.
- Google на самом деле разработал алгоритмы, чтобы предотвратить влияние дублирующего контента на веб-мастеров. Эти алгоритмы группируют различные версии в кластер, отображается «лучший» URL в кластере, и они фактически объединяют различные сигналы (например, ссылки) со страниц в этом кластере на отображаемый. Они даже дошли до поговорка «Если вы не хотите беспокоиться о сортировке дубликатов на вашем сайте, вы можете позволить нам беспокоиться об этом».
- Дублированный контент не является основанием для действий, если он не предназначен для манипулирования результатами поиска.
- Самое худшее, что может случиться при такой фильтрации, - это то, что менее желательная версия страницы будет отображаться в результатах поиска.
- Google пытается определить первоначальный источник контента и отобразить его.
- Если кто-то копирует ваш контент без разрешения, вы можете запросить его удаление подача запроса в соответствии с законом об авторском праве цифрового тысячелетия.
- Не блокируйте доступ к дублированному контенту. Если они не могут сканировать все версии, они не могут объединить сигналы.
Источники:
Ловко иметь дело с дублированным контентом
Дублированный контент из-за скребков
Google, дублированный контент, вызванный параметрами URL, и вы
Встреча на высшем уровне с дублированием контента в SMX Advanced
Узнайте влияние дубликатов URL
Дублированный контент (Справка консоли поиска)
Причины дублирования контента
- HTTP и HTTPS
- www и не www
- Параметры и граненая навигация
- Идентификаторы сессии
- Конечные косые черты
- Индексные страницы
- Альтернативные версии страницы, такие как m. или AMP страниц или распечатать
- Среды разработки / хостинга
- пагинация
- Скреперы
- Страновые / языковые версии
Решения для дублирования контента
Решение будет зависеть от конкретной ситуации:
- Ничего не делайте и надеюсь, что Google все сделает правильно Хотя я бы не рекомендовал этот курс действий, вы, возможно, уже читали, что Google будет кластеризовать страницы и объединять сигналы, эффективно обрабатывая проблемы с дублирующимся контентом для вас.
- Канонические метки. Эти теги используются для объединения сигналов и выбора предпочтительной версии. Моя любимая мозоль, когда на сайте правильно установлены канонические теги, и я вижу аудит, который говорит, что есть проблемы с дублированием контента. Это не проблема в этот момент, так что не говорите, что это так.
- 301 перенаправляет. Это предотвратит большинство проблем с дублированием страниц, поскольку некоторые альтернативные версии не будут отображаться.
- Скажите Google, как обрабатывать параметры URL. Их настройка сообщает Google, что на самом деле делают параметры, вместо того, чтобы позволить им попытаться выяснить это.
- Rel =»альтернативный». Используется для консолидации альтернативных версий страницы, таких как мобильные или страницы разных стран / языков. В частности, для страны / языка hreflang используется для отображения правильной страницы страны / языка в результатах поиска. Несколько месяцев назад Google Джон Мюллер , отвечая на вопрос в видеовстрече для веб-мастеров сказал, что исправление hreflang не повысит рейтинг, а только поможет показать правильную версию. Вероятно, это связано с тем, что Google уже определил альтернативные версии и объединил сигналы для разных страниц.
- Rel = ”prev” и rel = ”next”. Используется для нумерации страниц.
- Следуйте рекомендациям синдикации ,
TL; DR
Есть некоторые вещи, которые на самом деле могут вызвать проблемы, такие как очистка / спам, но по большей части проблемы будут вызваны самими веб-сайтами. Не запрещайте в robots.txt, не делайте nofollow, noindex, не канонизируйте страницы, предназначенные для длинных хвостов, и страницы обзорного типа, но используйте упомянутые выше сигналы для решения ваших конкретных проблем, чтобы указать, как вы хочу, чтобы содержимое было обработано. Проверять, выписываться Раздел справки Google по дублированному контенту ,
Мифы о штрафах за дублированный контент должны умереть. Аудитам, инструментам и недоразумениям нужна правильная информация, иначе этот миф может существовать еще 10 лет. Существует множество способов объединить сигналы на нескольких страницах, и даже если вы их не используете, Google попытается объединить сигналы для вас.
Мнения, выраженные в этой статье, принадлежат автору гостя и не обязательно относятся к Search Engine Land. Штатные авторы перечислены Вот ,
Об авторе
Что такое дублированный контент?Сколько в Интернете дублируется?
Что думают Google по поводу дублированного контента?
Что такое дублированный контент?
Сколько в Интернете дублируется?